
Chaohui Yu
DAMO Academy, Alibaba Group
- superhuiych [at] gmail.com
- Google Scholar
I'm an algorithm engineer at DAMO Academy, Alibaba Group. Before this, I got my Master degree and Bachelor degree from Institute of Computing Technology (ICT) and Shandong University in 2020 and 2017, respectively. My research interest includes: Transfer Learning, Object Detection/Segmentation, Semi/Self-supervised Learning, Multimodal Learning, image/video/3D/4D Generation, and related applications.
 ] [
] [ ] [LINK]
] [LINK]



3DV-TON: Textured 3D-Guided Consistent Video Try-on via Diffusion Models
The ACM International Conference on Multimedia. (ACMMM-25)

AnimateAnyMesh: A Feed-Forward 4D Foundation Model for Text-Driven Universal Mesh Animation
The International Conference on Computer Vision. (ICCV-25)

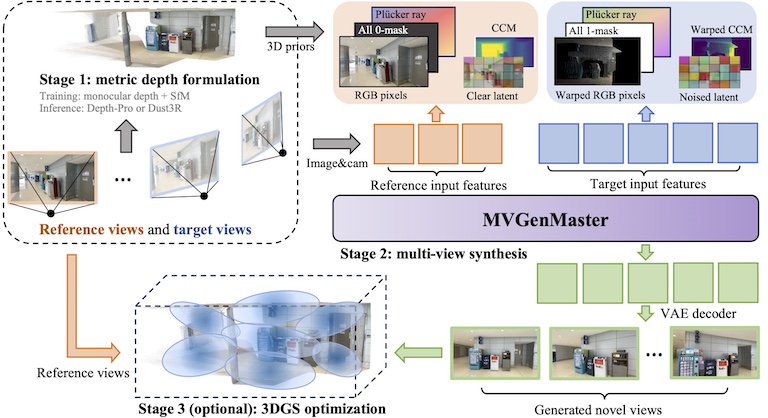
MVGenMaster: Scaling Multi-View Generation from Any Image via 3D Priors Enhanced Diffusion Model
The Conference on Computer Vision and Pattern Recognition (CVPR-25)
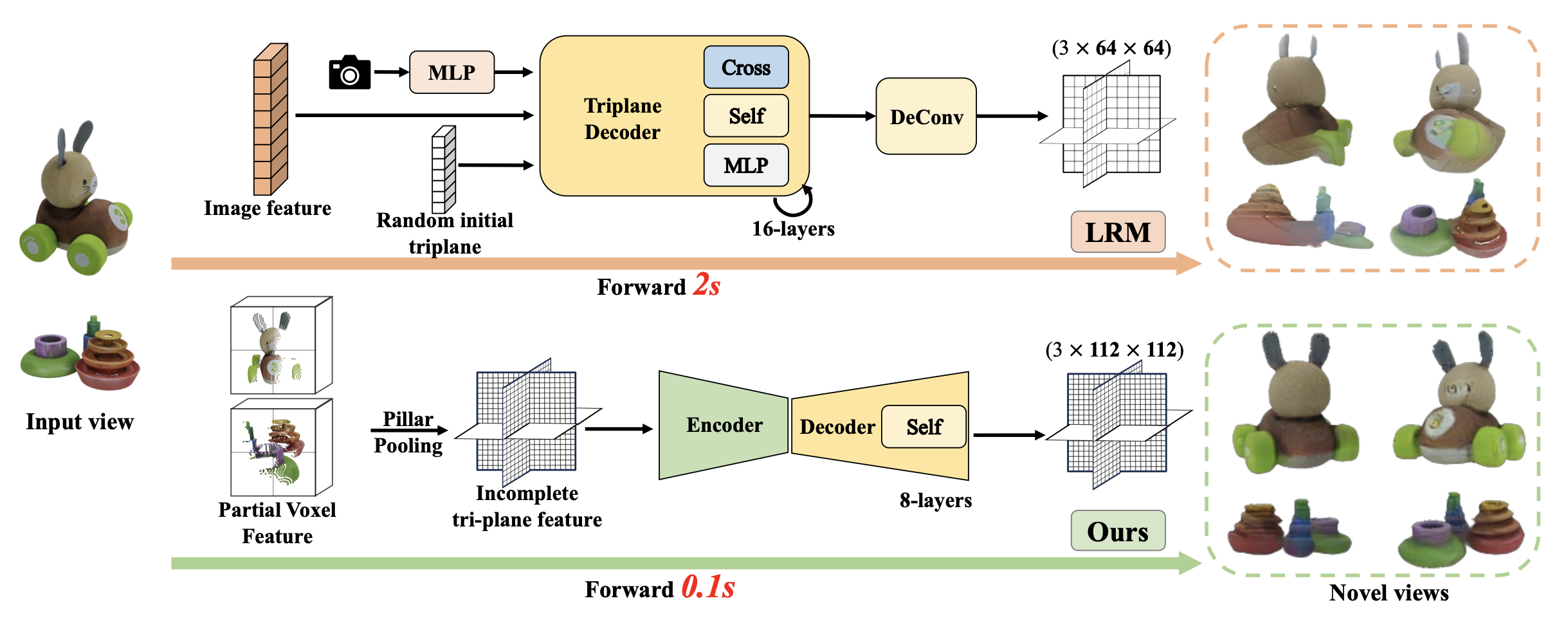
LPM: Efficient 3D Content Creation from Single Image by Large-Scale Partial 3D Modeling.
IEEE Transactions on Circuits and Systems for Video Technology (TCSVT-25)
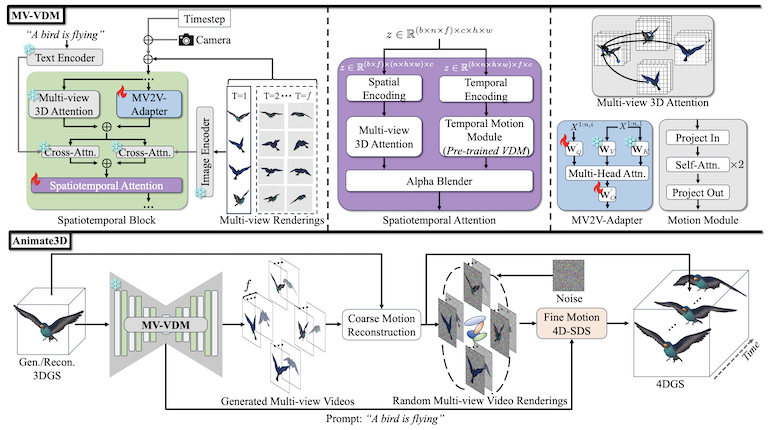
Animate3D: Animating Any 3D Model with Multi-view Video Diffusion
Neural Information Processing Systems. (NeurIPS-24)
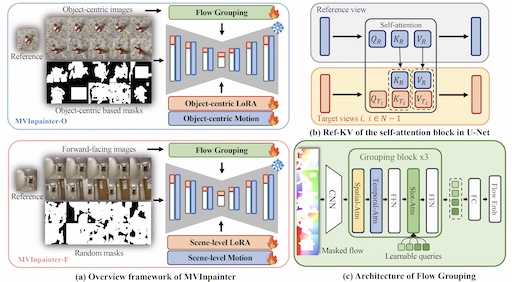
MVInpainter: Learning Multi-View Consistent Inpainting to Bridge 2D and 3D Editing
Neural Information Processing Systems. (NeurIPS-24)
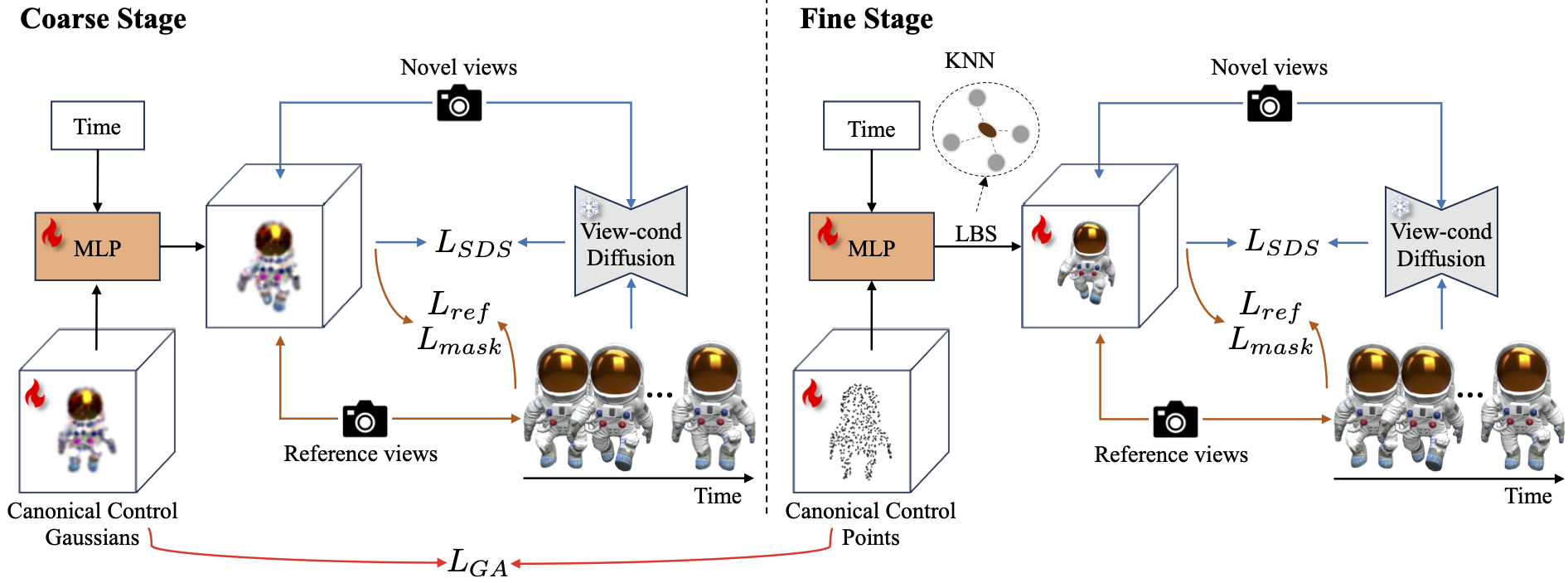
SC4D: Sparse-Controlled Video-to-4D Generation and Motion Transfer
European Conference on Computer Vision. (ECCV-24)
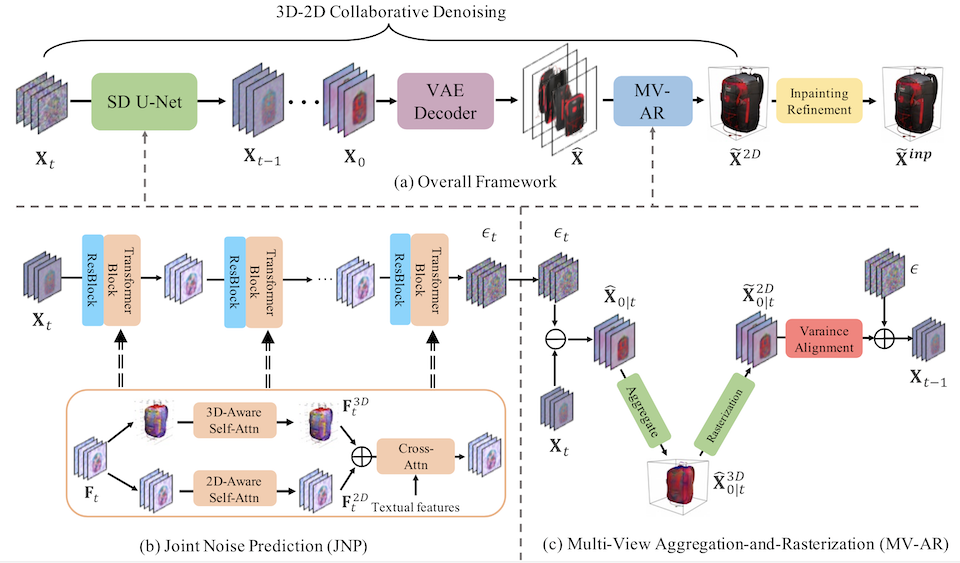
VCD-Texture: Variance Alignment based 3D-2D Co-Denoising for Text-Guided Texturing
European Conference on Computer Vision. (ECCV-24)

MeshSegmenter: Zero-Shot Mesh Semantic Segmentation via Texture Synthesis
European Conference on Computer Vision. (ECCV-24)

Points-to-3D: Bridging the Gap between Sparse Points and Shape-Controllable Text-to-3D Generation
The 31th ACM International Conference on Multimedia. (ACMMM-23)
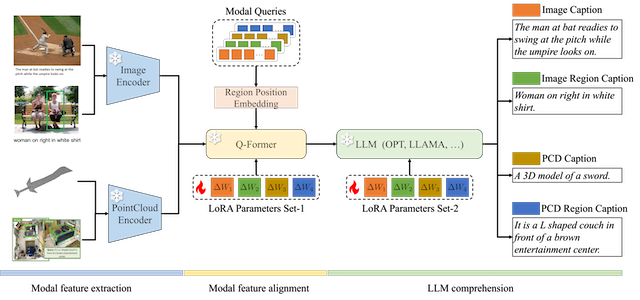
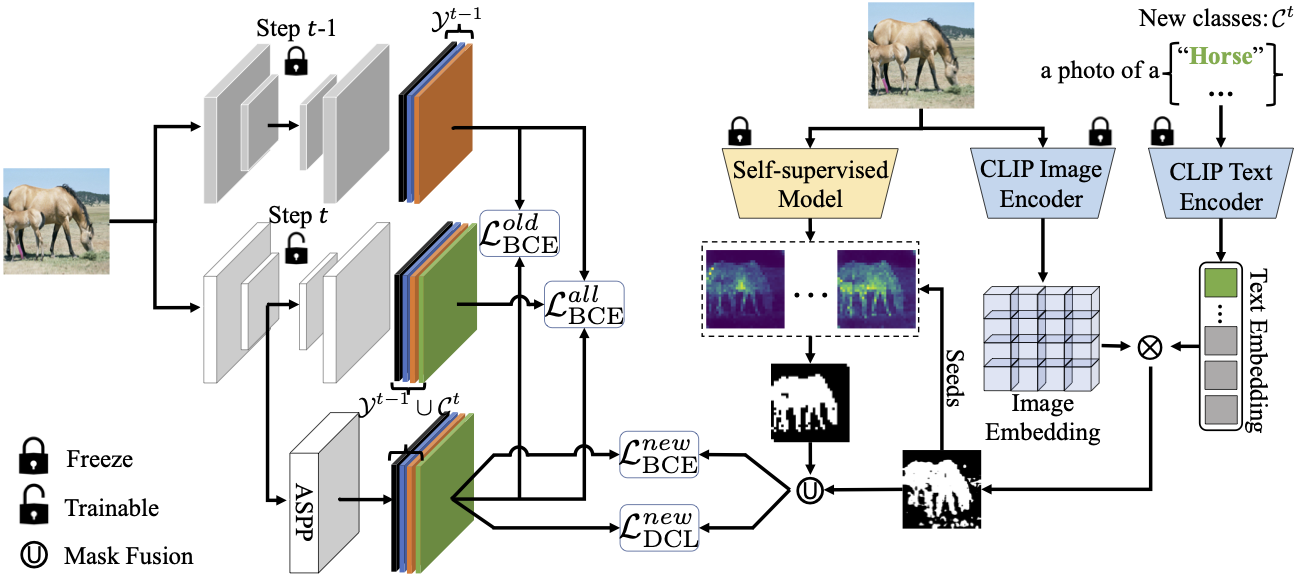
Foundation Model Drives Weakly Incremental Learning for Semantic Segmentation
The Conference on Computer Vision and Pattern Recognition (CVPR-23)
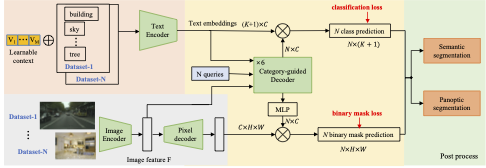
LMSeg: Language-guided Multi-dataset Segmentation
The International Conference on Learning Representations 2023. (ICLR-23)
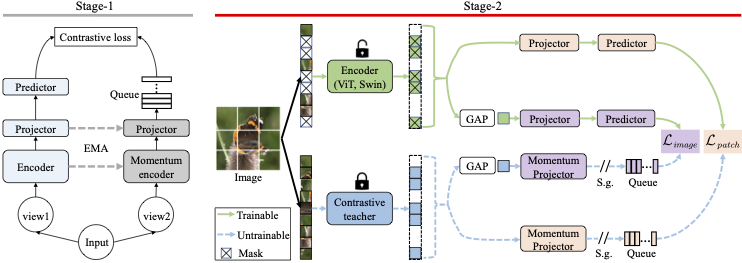
MimCo: Masked Image Modeling Pre-training with Contrastive Teacher
The 30th ACM International Conference on Multimedia. (ACMMM-22)